JabRef GSoC’21 Projects
Hey everyone, Today’s blog is about the projects selected for GSoC and a little sneak peek into the projects.
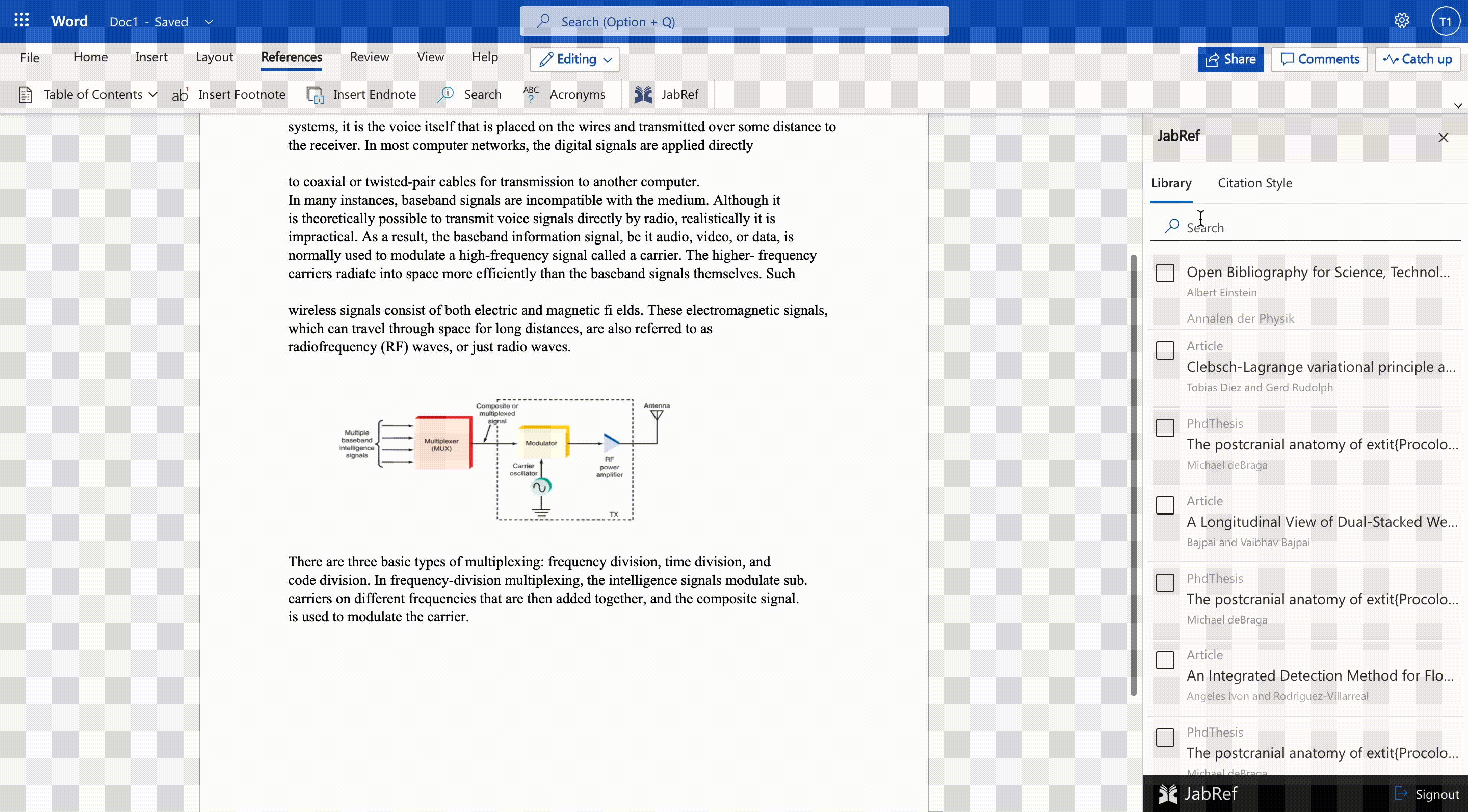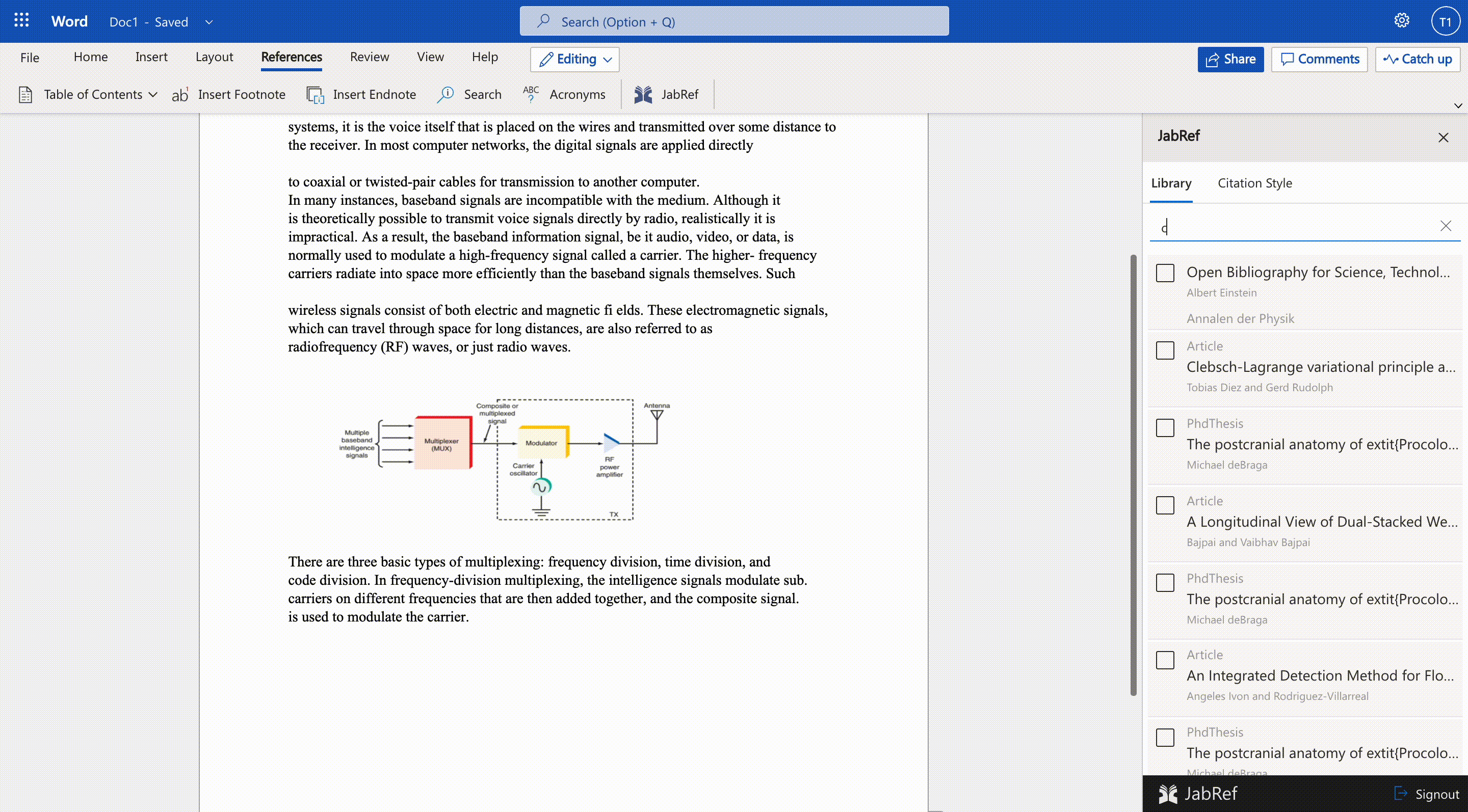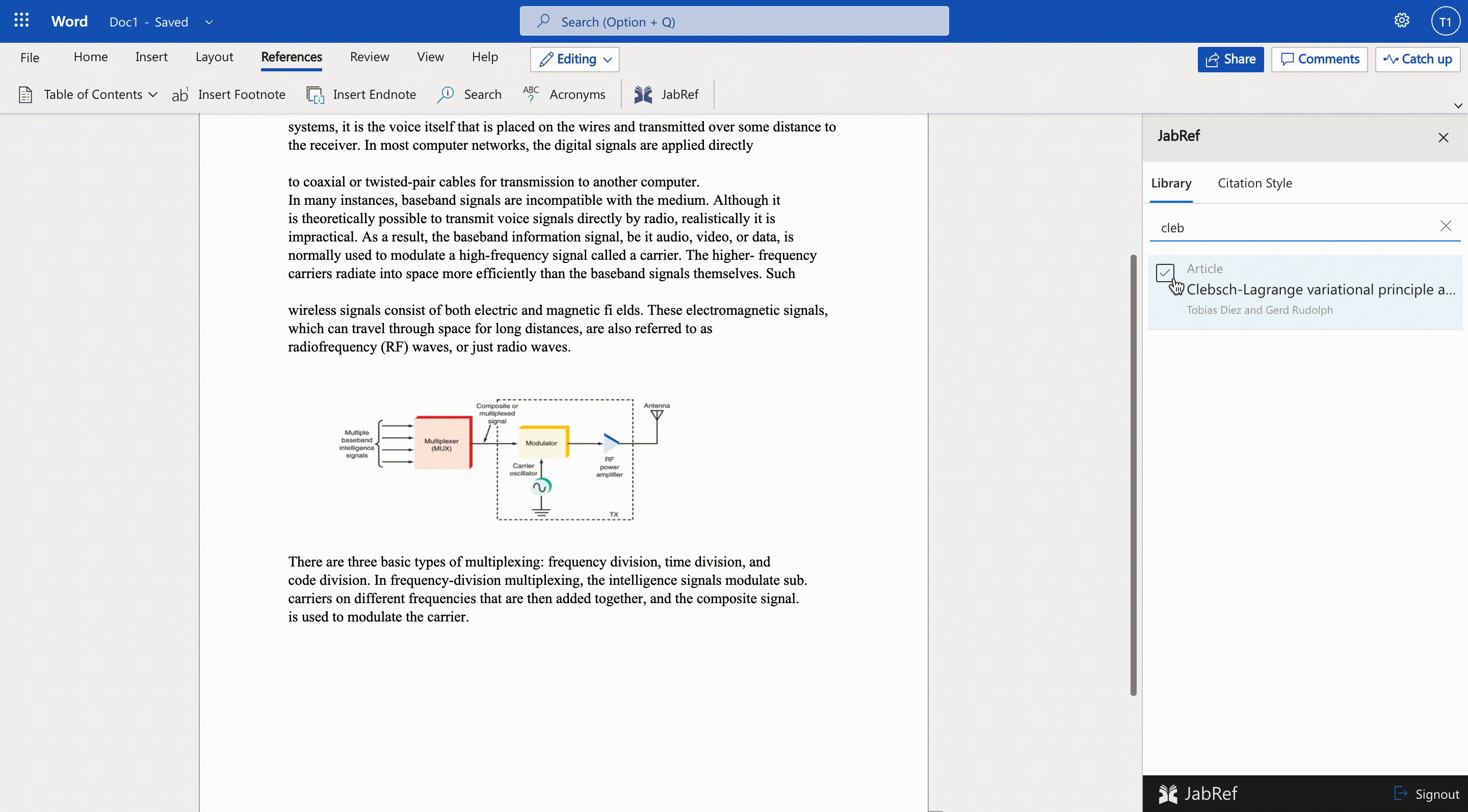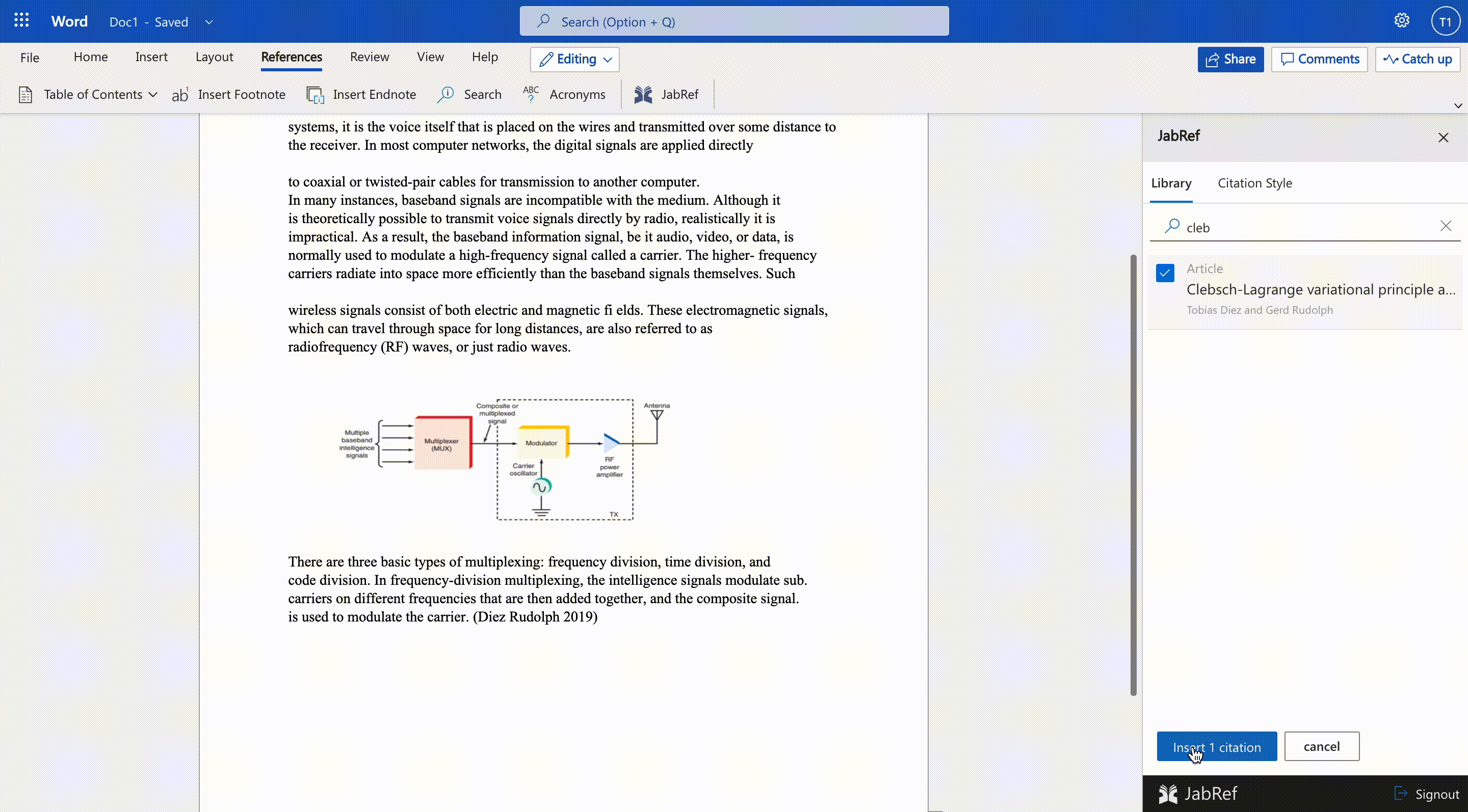
Microsoft Word Integration
We are working on a Word add-in that allows users to select and insert citations directly from the Word document. The JabRef Word Add-in can be used without having your reference manager open or even installed. Once you sign in to JabRef Word Addin, your JabRef library is downloaded from the cloud, and you can continue working on your document. JabRef word addin opens as a separate panel in Word alongside your document window. So your whole document remains in your view as you search, select and insert references.
For more information about the project, visit the links below.
- GitHub: JabRef Word Addin
- Mentors: @Siedlerchr, @Tobiasdiez, @JonatanAsketorp
- Mentee: @Mohit
Improved PDF Integration
The second project is all about PDFs and is split into two main goals: Fulltext search in linked PDFs and metadata extraction from new pdfs.
The people involved are:
- Mentors: @Koppor, @Calixtus, @DominikVoigt
- Mentee: @Btut
Fulltext search
Over the duration of a scientists career, bibliographies tend to grow large in size. Currently, JabRef users can filter their bibliography by performing a search in the bib-entries. This search only looks for matches in the fields of the bibentry, but not in the linked documents. We want to change that by indexing all linked documents using Apache Lucene. Additionally to the filtering in the table of entries, users are presented with a tab in the entry-editor containing a google-esque visualization of the matched text portions in the PDFs. Progress can be tracked here.
Metadata extraction
An important aspect of a library is the ability to share items with others. The de-facto way of sharing work in the scientific community is to share PDF files. Unfortunately, most of the times, it is hard to automatically deduce metadata needed to build a JabRef entry from a PDF alone. We want to integrate with GROBID, a machine learning library for extracting metadata from raw PDF documents. GROBID is learned to deduce the metadata from the content itself, as a human would. Checkout the corresponding issue for more information.